Abstract
In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce.
Overview
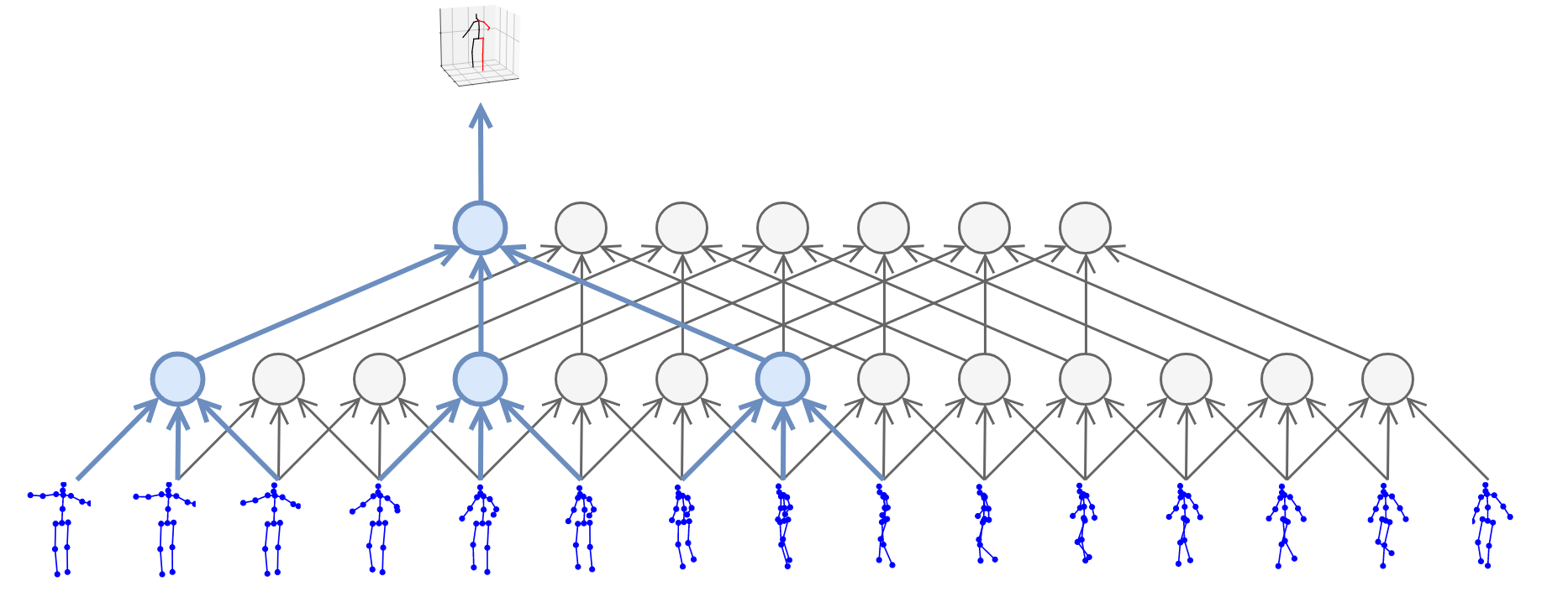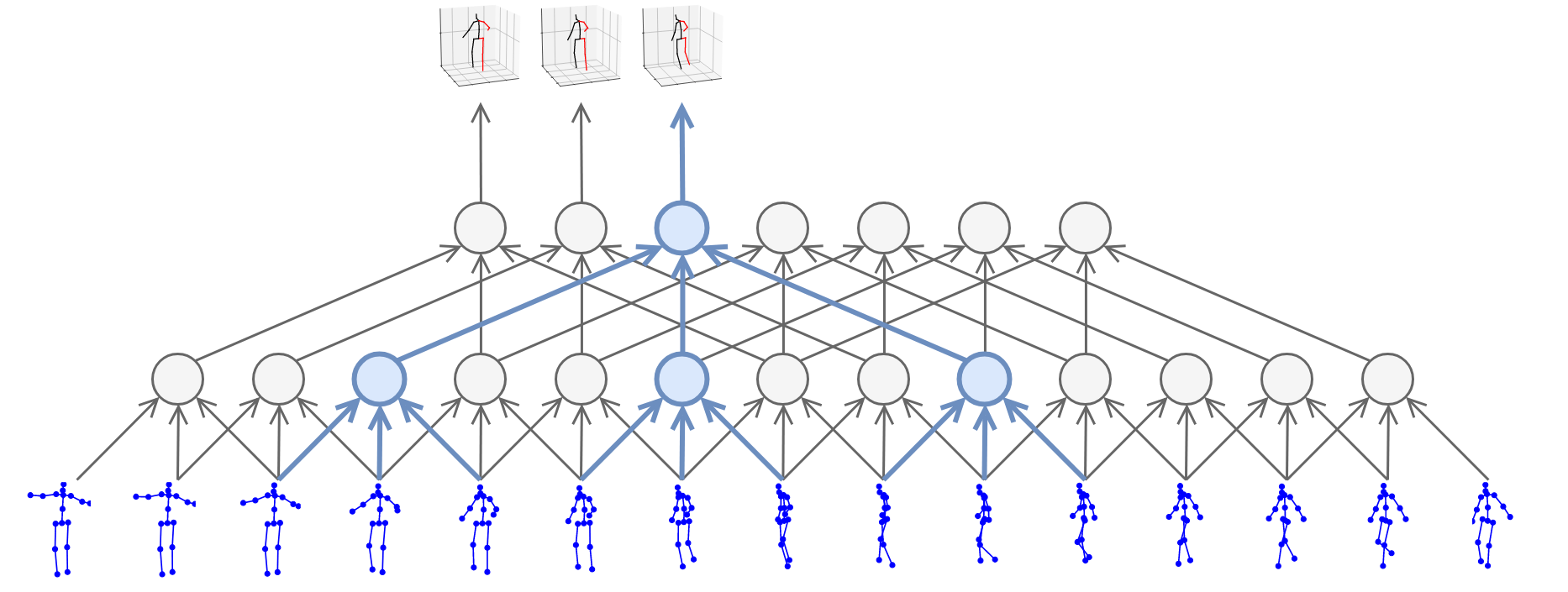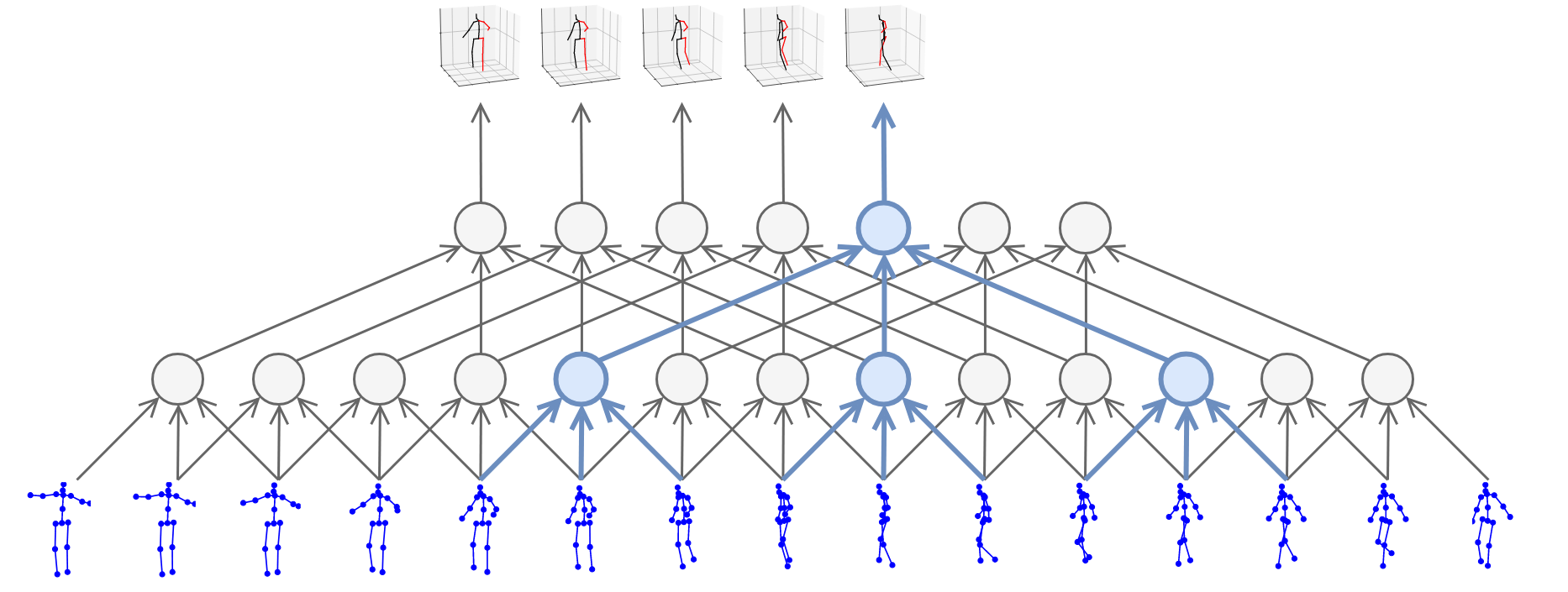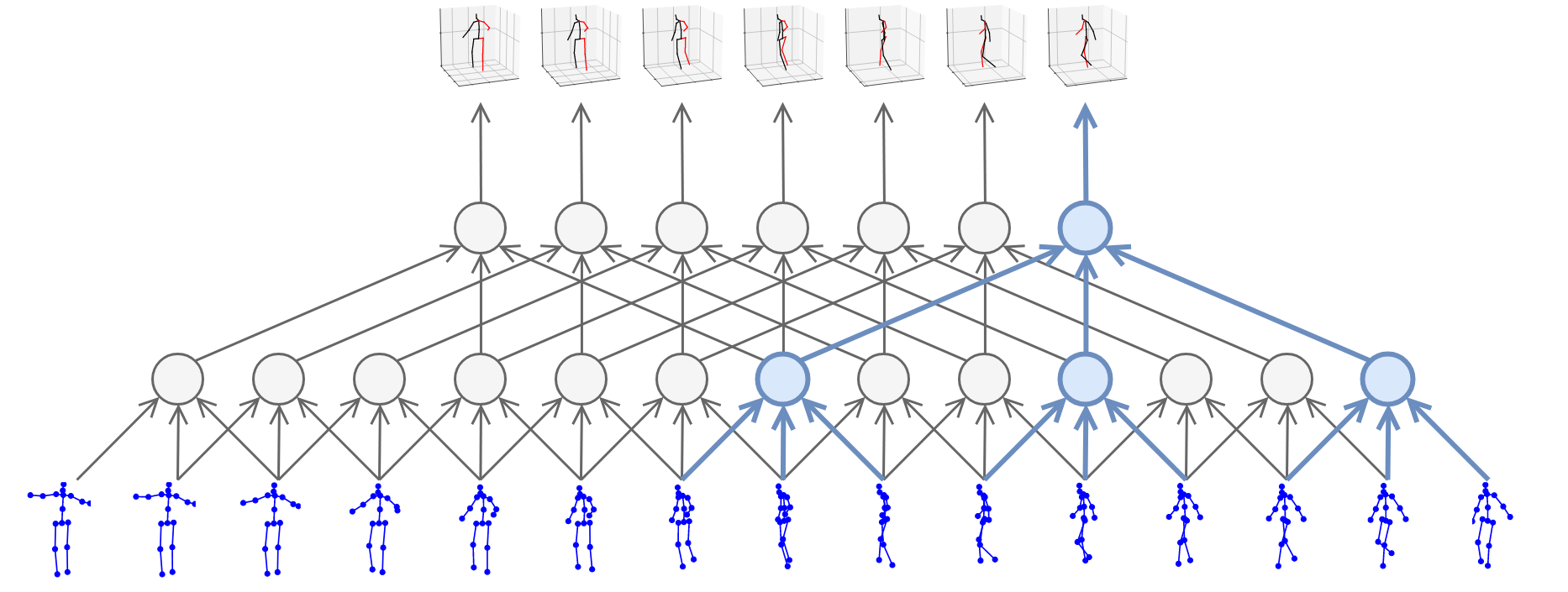
We build on the approach of state-of-the-art methods which formulate the problem as 2D keypoint detection followed by 3D pose estimation. While splitting up the problem arguably reduces the difficulty of the task, it is inherently ambiguous as multiple 3D poses can map to the same 2D keypoints. Previous work tackled this ambiguity by modeling temporal information with recurrent neural networks. By contrast, we adopt a convolutional approach which performs 1D dilated convolutions across time to cover a large receptive field. Compared to approaches relying on RNNs, it provides higher accuracy, simplicity, as well as efficiency, both in terms of computational complexity as well as the number of parameters. Additionally, convolutional models enable parallel processing of multiple frames which is not possible with recurrent networks.
Semi-supervised learning via back-projection
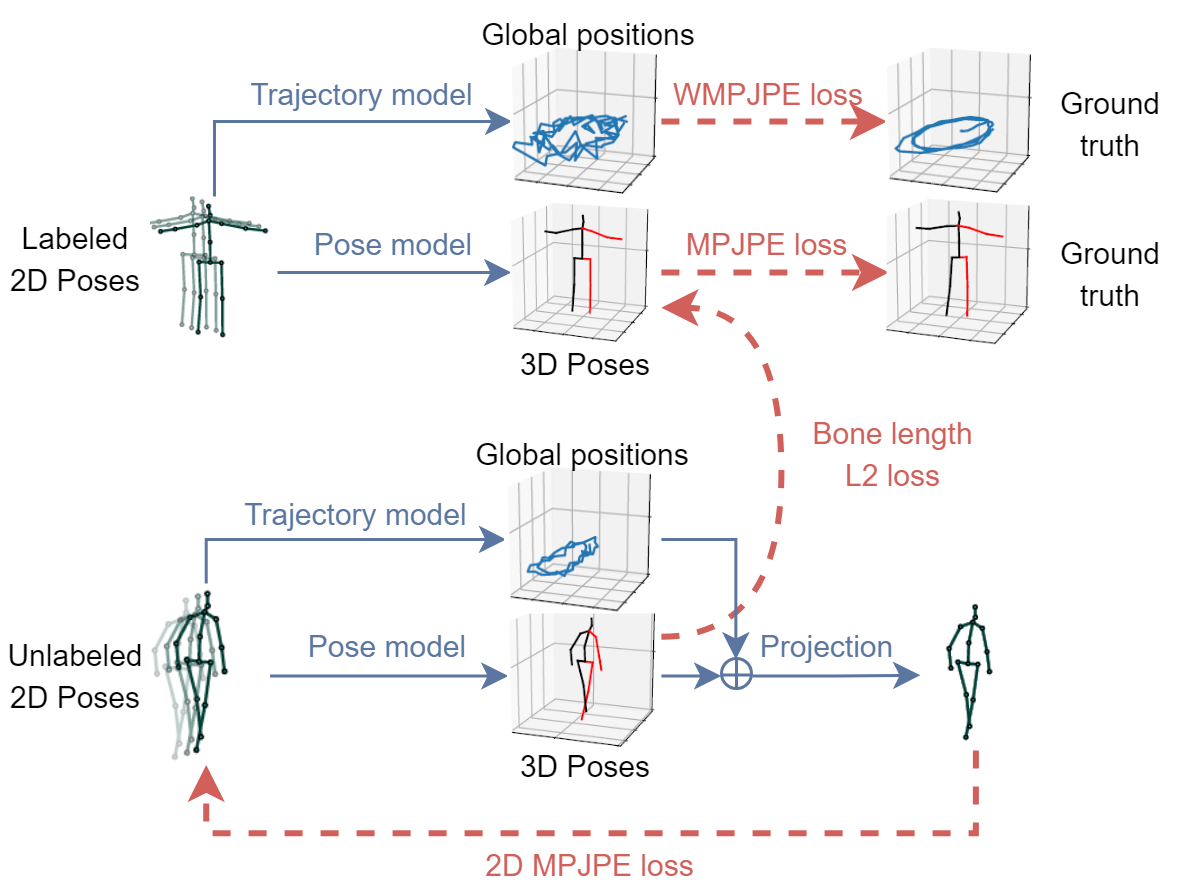
Equipped with a highly accurate and efficient architecture, we turn to settings where labeled training data is scarce and introduce a new scheme to leverage unlabeled video data for semi-supervised training. Low resource settings are particularly challenging for neural network models which require large amounts of labeled training data and collecting labels for 3D human pose estimation requires an expensive motion capture setup as well as lengthy recording sessions. Our method is inspired by unsupervised machine translation, where a sentence available in only a single language is translated to another language and then back into the original language. Specifically, we predict 2D keypoints for an unlabeled video with an off the shelf 2D keypoint detector, predict 3D poses, and then map these back to 2D space.
The key idea is to solve an autoencoding problem with the unlabeled data where the 3D pose estimator is used as the encoder and the predicted poses are then mapped back to 2D space, based on which a reconstruction loss can be computed. Due to the perspective projection, the 2D pose on the screen depends both on the trajectory (i.e. the position of the human referential in space at each time step) and the 3D pose (the position of joints in the human referential). We therefore also regress the 3D trajectory of the person, so that the back-projection to 2D can be performed correctly. At this stage, however, the model has no incentive to predict a plausible 3D pose and might just learn to copy the input (i.e. predict a flattened 3D pose). To avoid this, we add a soft constraint to approximately match the mean bone lengths of the subjects in the unlabeled batch to the subjects of the labeled batch.
Results
Our model achieves state-of-the-art results on Human3.6M and HumanEva-I. We provide below an overview of the main Human3.6M results with various keypoint detectors and architectures.
| 2D Detections | BBoxes | Blocks | Receptive Field | Error (P1) | Error (P2) |
|---|---|---|---|---|---|
| CPN | Mask R-CNN | 4 | 243 frames | 46.8 mm | 36.5 mm |
| CPN | Ground truth | 4 | 243 frames | 47.1 mm | 36.8 mm |
| CPN | Ground truth | 3 | 81 frames | 47.7 mm | 37.2 mm |
| CPN | Ground truth | 2 | 27 frames | 48.8 mm | 38.0 mm |
| Mask R-CNN | Mask R-CNN | 4 | 243 frames | 51.6 mm | 40.3 mm |
| Ground truth | – | 4 | 243 frames | 37.2 mm | 27.2 mm |
Demo
Demos in the wild
Our model generates a smooth reconstruction even on YouTube videos.
Single-image model vs temporal model
Compared to a single-frame baseline, our temporal model exploits time to resolve pose ambiguities and reduces jitter/noise.
Human3.6M
HumanEva-I
Reference
@inproceedings{pavllo:videopose3d:2019,
title={3D human pose estimation in video with temporal convolutions and semi-supervised training},
author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}